Recently I migrated one of my libraries (Emperror) to a vanity import path. Although the migration itself was easy (took less than one day), making the decision, thinking it through from every angle to make sure existing applications don’t break, wasn’t. I did a lot of research to find the right migration path, URL, tooling and I decided to share my experience in this post.
Update (2020-01-22): Add a section about go. and .dev domains
Vanity import paths
Go 1 introduced a mechanism for custom or “vanity” import paths.
In addition to the common hosting sites (GitHub, Bitbucket, etc) and custom VCS URLs (.git, .hg, etc) known to the go command,
this mechanism can be used to point a custom URL to any of the above listed services. For example,
emperror.dev/errors currently points to a Git repository on GitHub.
Apart from the nicer import paths, this gives you full control over your package which matches Go’s decentralized package management philosophy perfectly. By establishing a stable import path, you get the ability to move your code from one “physical” place (hosting provider, organizational unit, etc) to another.
Vanity import paths work by serving a webpage with HTML meta tags containing repository information. For example, emperror.dev/errors has the following meta tag:
<meta name="go-import" content="emperror.dev/errors git https://github.com/emperror/errors">
or generally:
<meta name="go-import" content="import-prefix vcs repo-root">
When you run go get emperror.dev/errors, the go tool sends an HTTP request to the import URL
to fetch the repository information, then downloads the code as usual.
In addition to the import information, you can (optionally) add details about the source code
via the go-source meta header. This tells godoc how to link to the source code of your package:
<meta name="go-source" content="emperror.dev/errors https://github.com/emperror/errors https://github.com/emperror/errors/tree/master{/dir} https://github.com/emperror/errors/blob/master{/dir}/{file}#L{line}">
In this case, godoc will directly link to source files on GitHub.
It’s worth mentioning that there was a proposal for DNS based vanity imports, but it was rejected. Although many people find setting vanity imports up cumbersome (and for these people DNS based imports would have been a relief), there is an increasing number of tools and practices around vanity imports (which will be discussed in this post later).
Trust issues
If I’m being completely honest, trust was a major concern when I first considered using vanity imports, both as a package author and a package consumer:
- What happens if I/the package author lose(s) control over the domain?
- What happens if I/the package author misconfigure(s) something (eg. DNS)?
- What happens if the web server behind a vanity import goes down?
Although these are legitimate questions, the truth is that every remote import path (not just vanity imports) is prone to these risks:
- GitHub can go down
- the package author can delete the repository containing the code
- accounts can get hacked (password leaked, etc)
The only real protection against these risks is vendoring. Alternatively, the replace directive can give some control to the user when using Go modules.
On the other hand, a vanity import sends a clear message: “This isn’t just a toy project I uploaded to GitHub.”
Non vanity import paths are considered harmful. If you are a serious project, enforce a vanity import path. #golang
— Jaana Dogan ヤナ ドガン (@rakyll) August 2, 2017
So ultimately I realized that publishing packages under a vanity import path is not at all worse than any other remote import path (from a trust/stability point of view), and it even sends a positive message.
Choosing an import path
The first step of setting up a new vanity import path is choosing one. There is a good number of examples available on the internet:
rsc.io/pdf: Import path under a personal domainknative.dev/pkg: Import path under an organizational/project domaingocloud.dev: Import path is a root domain itselfcontrib.go.opencensus.io/exporter/jaeger: Import path is under a subdomain
Personally, I prefer the first two: good import paths are short, but meaningful.
When choosing a domain, keep in mind that it will be the name of your package for the foreseeable future,
so choose a name that you’ll still like tomorrow.
People tend to choose domains with .io and .dev TLDs for their pacakges/software projects these days.
Setting up a website
Once you have a domain and decided on the import path, the next step is setting up a website. If you already have one, your job is easy: just insert the necessary HTML meta tags in the source code.
Dynamic websites are easy to update: chances are you have to change a template and you are done. Static sites (especially if they are not generated) are a different story.
Let’s take a look at a few tools and techniques.
Configuring a web server
The easiest way to set up vanity imports (especially if you already have a website up and running) is
configuring a web server to catch requests from the go command.
But how can we differentiate regular requests and requests from the go command?
Fortunately the Go authors thought about this:
every time go fetches vanity import URLs, it sets a query parameter in the URL:
https://emperror.dev/errors?go-get=1
You can write a conditional logic in your web server config (eg. nginx) to handle Go requests differently and serve the HTML meta tags. With this solution you can set up vanity imports without changing an existing website’s code. While this should work sufficiently enough, read on for better solutions.
Vanity import services
If you don’t already have a website and you don’t plan to add content to it, or just want to get up and running quickly you can use a vanity import service, for example:
These services usually accept a declarative configuration file containing the list of packages and repositories:
host: example.com
cache_max_age: 3600
paths:
/foo:
repo: https://github.com/example/foo
vcs: git
Compared to other solutions (like static sites) this has a huge disadvantage: you have to run it 24 / 7 for the rest of your (package’s) life which is a major commitment. Not to mention the fact that these services rarely give you any control over the website content.
Vanity import generators
Vanity import generators represent a transition between vanity import services and static site generators. They are mostly useful for quickly setting up and running new vanity import paths, but since they generate static content, you don’t have to commit yourself to running an application (other then a web server, which you might already have).
One great example for these generators is vangen. (At the time of this writing, the site under emperror.dev/errors is generated by vangen)
It accepts a simple configuration (you can also find it here):
{
"domain": "emperror.dev",
"repositories": [
{
"prefix": "errors",
"subs": [
"utils/keyval"
],
"url": "https://github.com/emperror/errors"
}
]
}
Obviously the generated site needs to live somewhere. If you don’t already have a web server, services like Netlify and GitHub Pages are great candidates for hosting it.
Note: Although I do have a web server running on a personal VPS, I stil decided to use Netlify for emperror.dev.
That way I don’t have to worry about anything if I press AZ-5 on my server.
Static site generators
I consider static site generators to be the best solution for vanity import paths at the moment. They are perfect for project websites (as well), but chances are you are going to miss the declarative configuration.
Static site generators usually have some sort of templating which you can modify to contain the necessary HTML meta tags. Nate Finch did a great job explaining the process for Hugo in his post, but the instructions there should work for other static site generators as well.
+1: Configure redirects in a hosting service
While preparing for this blog post I came across a clever trick in the Knative project’s website repository. Their website is generated using Hugo and is hosted on Netlify. I really like Netlify, because they provide a plethora of features to their users, including Redirects.
The trick is really simple (and similar to configuring a web server): set up redirects with a query parameter condition:
/build/* go-get=1 /golang/build.html 200
The targets of the redirects are static files with the necessary HTML meta tags. Although this solution is probably simpler than configuring a static site builder, it is also specific to Netlify, so in case you need to move your site to a different provider, you either have to make sure they provide a similar feature or use the static site generator to serve the meta tags.
Best practices
Use HTTPS
Although the go command supports HTTP URLs, HTTPS is a requirement these days.
Let’s Encrypt made HTTPS free for everyone and most static site hosting services
(Netlify, GitHub Pages, etc) provide Let’s Encrypt integration,
so setting up an HTTPS URL is trivial.
An interesting phenomenon to see is the increasing number of vanity import paths that use .dev domains.
Although it’s a perfect use case,
there is a common misconception that they “use HTTPS by default”.
In fact, every .dev domain is on the HSTS preload list,
which makes HTTPS required in browsers, but has no effect on the go command whatsoever.
Canonical import paths
As of Go 1.4, a package can define a canonical import path:
package errors // import "emperror.dev/errors"
If the go command detects an “import comment”,
it rejects every other package import path that may resolve to the same package.
For example, go get rejects the following:
go get github.com/emperror/errors
It’s worth mentioning that Go modules already provide canonical import paths, but nevertheless it makes sense to add the import comment for older Go versions.
Website content
In addition to the meta tags in the HTML, it’s worth adding some content to the website (instead of serving a blank page).
Obviously the best thing you can do for your users is serving some meaningful content, like documentation. If you already use a static site generator (like Hugo), it’s trivial.
However, setting up a website with content is usually not the first step in the lifecycle of a software project. There are two common practices that you can quickly set up and running (before writing pages of documentation):
The first one is redirecting the page to godoc.org. You can do that via HTML meta tags:
<meta http-equiv="refresh" content="0; url=https://godoc.org/emperror.dev/errors" />
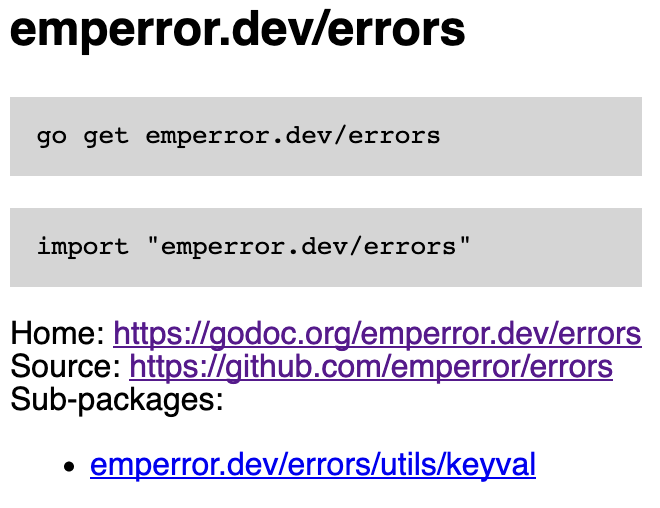
The second one is serving a very simple index page, containing:
go getcommand- import statement
- link to the repository
- link to the godoc page
Here is a simple example, generated by vangen:
go. subdomain
This isn’t really a best practice, but has a few advantages over using a root domain.
By putting all your go packages under a subdomain like go.mydomain.com,
you don’t have to paste meta tags into your website
(or worse: serve alternate content based on a URL query parameter).
In a large organization keeping things separate (limiting access) is usually desirable.
Furthermore, you can serve different content for consumers under the two different domains.
For example, mydomain.com/myproduct can serve your product page,
while go.mydomain.com/myproduct can redirect to GoDoc.
k8s.io packages illustrate why this can save developers from frustration:
visiting the package URL in your browser usually lands you on a nice 404 page.
Last, but not least: a dedicated subdomain for your Go packages can also serve as an index for them. You can list all your packages there, share some basic info (version, supported Go version, etc).
Some real life examples applying this pattern:
- go.uber.org (package index)
- go.opencensus.io (redirects to GoDoc)
.dev domain
Similar to the pattern above you can choose to buy a domain with a .dev TLD
for your developer resources. Nothing keeps you from even combining the two and use go.mydomain.dev as a package root.
Conclusion
Using vanity import paths is a great way to decouple your packages from the VCS repository and tell the world that your project is serious. Furthermore, they let you create nice and memorable URLs.
If you intend to maintain a serious project for the long term, it definitely make sense to choose a vanity import path for it.
Further reading
https://golang.org/cmd/go/#hdr-Remote_import_paths
https://golang.org/s/go14customimport
https://npf.io/2016/10/vanity-imports-with-hugo/
https://blog.samwhited.com/2017/08/musings-on-the-future-of-go-package-management/